Das unterschätzte Auswahlkriterium für KI-Modelle: Vertrauen.
Für die meisten Unternehmensanwendungen unterscheiden sich die Spitzenmodelle von Anthropic, OpenAI und Google kaum noch in messbarer Weise. Irgendwann hört die Benchmark-Tabelle auf zu helfen.
An diesem Punkt wird Vertrauen zum eigentlichen Auswahlkriterium. Zwei Beobachtungen der letzten Wochen machen das konkreter als jede abstrakte Diskussion darüber.
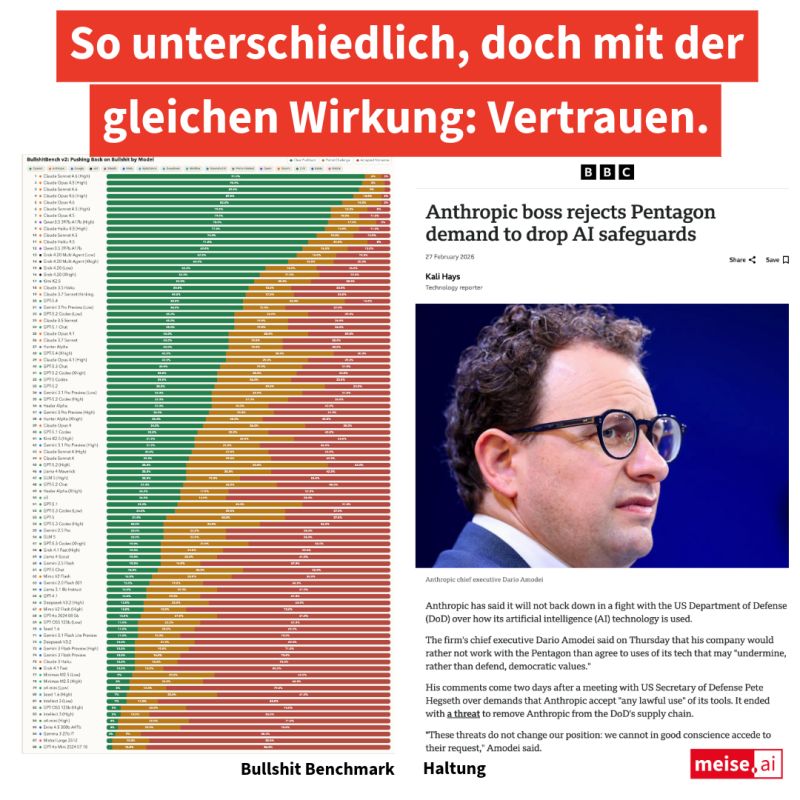
Peter Gostev von Arena.ai betreibt den BullshitBench: Fragen, die fachkundig klingen, aber keinen Sinn ergeben – und die Frage, ob das Modell das merkt. Die sieben Spitzenplätze belegen ausschließlich Claude-Varianten; OpenAI und Google liegen weit darunter, ohne erkennbare Verbesserung über Modellgenerationen hinweg.
Das ist weniger ein technisches Detail als ein Hinweis darauf, welches Verhalten beim Training priorisiert wurde. In Workflows, in denen nicht jede Antwort gegengeprüft wird, ist ein Modell, das auf inhaltlich kaputte Fragen selbstsicher antwortet, schlicht ein Risiko.
Die zweite Beobachtung betrifft die institutionelle Ebene. Anthropic hat Anfang März Regierungsverträge über 200 Millionen Dollar abgelehnt, weil das Pentagon freie Hand bei der Nutzung von Claude forderte.
CEO Dario Amodei hat zwei Ausnahmen durchgehalten: keine vollautonome Zielerfassung, keine Massenüberwachung. OpenAI hat den Deal gemacht. Die Reaktion der Nutzer war messbar – ChatGPT-Deinstallationen stiegen laut TechCrunch um 295 Prozent.
Natürlich ist das auch Strategie. Aber es gibt einen Unterschied zwischen einem Unternehmen, das Nutzerinteressen als Mittel zum Umsatz behandelt, und einem, das sie als Voraussetzung davon begreift.
Das Geschäftsmodell dahinter ist unspektakulär: Vertrauen zuerst, Wachstum danach. Dauert länger. Ist aber schwerer zu kopieren.
Sie wollen Ihr Team fit machen für das KI-Zeitalter? Im Kompetenz-Aufbau mache ich Ihre Führungskräfte und Teams fit für den produktiven KI-Einsatz — praxisnah und mit konkreten Use Cases.